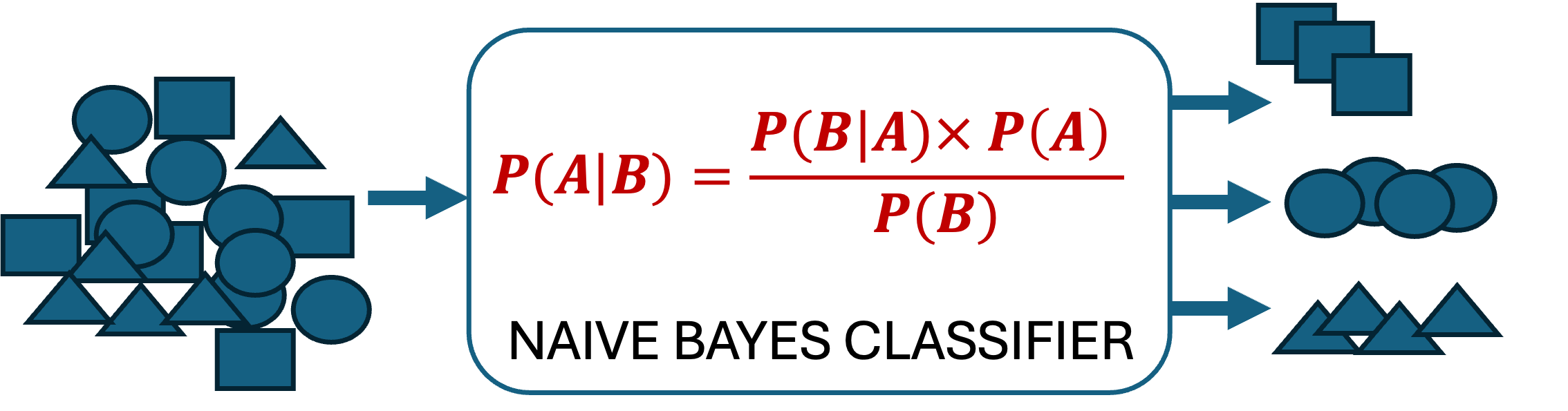In machine learning, algorithms can be broadly categorized into three paradigms: supervised learning, unsupervised learning, and reinforcement learning. In supervised learning, the goal is to learn a function that maps input features to output labels based on labeled training data. Within the class of models in supervised learning, there is a further distinction between generative models and discriminative models. It addresses their fundamental approaches to learning from data.
Discriminative models (like these we previously explored - SVM, logistic regression …), learn a decision boundary and use it to separate classes. Generative models focus on understanding how the data is generated.
We will start this chapter with a short overview of probability theory, which will enable us to introduce the main concepts needed for understanding generative models in machine learning. After that we will introduce generative models, we will compare them to discriminative models, and we will look into the details of one generative model, Naive Bayes.
9.1 Probabilities Primer with Examples
We will start with a short overview of the main concepts, definitions, and axioms in probability theory.
Sample Space: The set of all possible outcomes of an experiment is called the sample space, denoted by \(S\). This forms the universal set in the context of set theory.
Events: Any subset of the sample space is called an event. For example, if the experiment is tossing a coin, the sample space is \(S = \{Heads, Tails\}\). The event of getting heads is a subset \(\{Heads\}\).
Probability of an Event: The probability of an event \(A\), denoted \(P(A)\), is a measure of how likely event \(A\) is to occur.
Probability: Probability (in general) is represented by a number between 0 (impossible) and 1 (certain). For example, the probability of rolling a 6 on a standard six-sided die is 1/6. This is because there is one favorable outcome (rolling a 6) and six total possible outcomes (rolling a 1, 2, 3, 4, 5, or 6).
9.2 Axioms of Probability
Non-negativity: The probability of any event is always greater than or equal to zero: \(P(A) \geq 0\). For example, the probability of getting a 7 when throwing one die is 0. This aligns with set theory, as the number of elements in a set (including the empty set) cannot be negative.
Certainty: The probability of the entire sample space (all possible outcomes) is 1: \(P(S) = 1\). This corresponds to the idea that the universal set contains all possible elements, making the occurrence of an outcome within it certain.
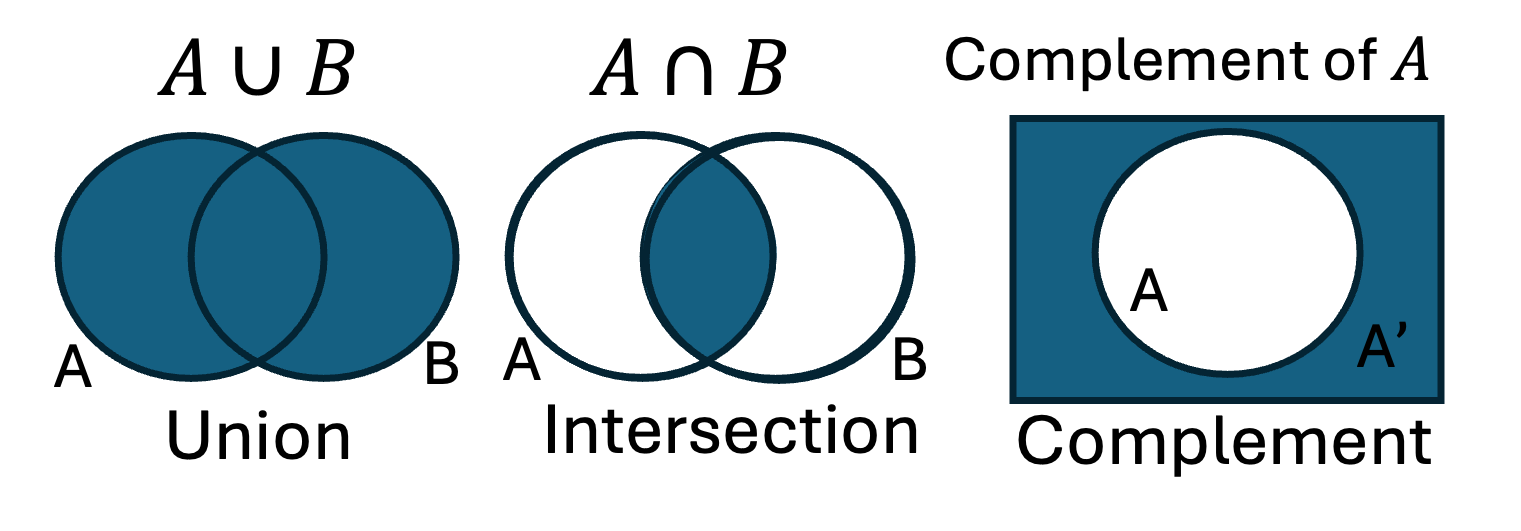
Additivity: For mutually exclusive events (events that cannot occur simultaneously), the probability of either event occurring is the sum of their individual probabilities: \(P(A \cup B) = P(A) + P(B)\). This is analogous to the set theory concept where the union of two disjoint sets contains all elements from both sets without repetition.
For any events, not necessarily mutually exclusive, the probability that either occurs is given by: \(𝑃(𝐴 ∪ 𝐵) = 𝑃(𝐴) + 𝑃(𝐵) − 𝑃(𝐴 ∩ 𝐵)\). This corresponds to the inclusion-exclusion principle in set theory. When finding the total number of elements in the union of two sets, we add the sizes of the individual sets and subtract the size of their intersection to avoid double-counting the common elements.
Here are some additional set operations and their probabilistic interpretations:
Union: \(A \cup B\) represents the event where either event \(A\) or event \(B\) occurs, or both. This is equivalent to the union of sets. The probability of the union of two events is the sum of their individual probabilities minus their joint probability (to avoid double-counting the case where both events occur).
Intersection: \(A \cap B\) represents the event where both events A and B occur. This corresponds to the intersection of sets. The probability of the intersection of two events is their joint probability.
Complement: \(A^c\) represents the event where A does not occur. This is equivalent to the complement of set A. The probability of the complement of an event is 1 minus the probability of the event.
Example: Consider rolling a die. The sample space is \(S = \{1, 2, 3, 4, 5, 6\}\).
Event \(A = \{2, 4, 6\}\) represents rolling an even number.
Event \(B = \{1, 2, 3\}\) represents rolling a number less than or equal to 3.
\(A \cup B = \{1, 2, 3, 4, 6\}\) is the event of rolling either an even number or a number less than or equal to 3.
\(A \cap B = \{2\}\) is the event of rolling a 2.
\(A^c = \{1, 3, 5\}\) is the event of rolling an odd number (the complement of event \(A\) as defined above).
The probability of rolling an even number is given by \(P(A) = P(2) + P(4) + P(6) = 1/6 + 1/6 + 1/6 = 1/2\).
Set operations
9.3 Joint and conditional probability
Probabilities can be marginal, joint, or conditional. Understandinding their differences is key to understanding ML models based on probabilistic reasoning.
Marginal probability is the probability of event occuring, \(P(A)\), not conditioned on other events. For example, this is the probability that a card drawn from a deck of cards is red \(P(red)=0.5\).
Joint Probability: This is the probability of two or more events happening at the same time. For independent events (events where the occurrence of one does not affect the occurrence of the other), the joint probability is calculated as the product of their individual probabilities: \(P(A \text{ and } B) = P(A \cap B) = P(A) \cdot P(B)\). Looking at the diagram with set operation, the symbol \(\cap\) corresponds to intersection, and specifies how two or more events, such as \(A\) and \(B\), occur at the same time.
For example, what is the probability of flipping heads on a coin and rolling a 4 on a die? These two events are independent (the outcome of the coin flip does not affect the outcome of the die roll). The probability of each event is 1/2 and 1/6 respectively. So, the joint probability is (1/2) * (1/6) = 1/12.
For dependent events (events where the occurrence of one affects the occurrence of the other), the joint probability is calculated using conditional probability: \(P(A \text{ and } B) = P(A) \cdot P(B \mid A)\). This formula states that the joint probability of A and B is the probability of A multiplied by the probability of B given that A has already occurred. For example, suppose you have a bag with 3 red balls and 2 blue balls. What is the probability of drawing a red ball, then another red ball without putting the first ball back in the bag?
The probability of drawing a red ball on the first draw is 3/5. After removing a red ball, there are only 2 red balls and 4 total balls left. So, the probability of drawing another red ball is 2/4. The joint probability of drawing two red balls in a row without replacement is then (3/5) * (2/4) = 3/10.
Conditional Probability: This measures the probability of an event B occurring given that another event A has already happened, denoted as \(P(B|A)\). It is calculated as:
\(P(B \mid A) = \frac{P(A \cap B)}{P(A)}\)
where \(P(A \cap B)\) represents the joint probability of both events occurring.
For example, consider a deck of cards.
Example 1: What’s the probability of drawing a King given that you know the card is a Heart? There are 13 Hearts and only one King of Hearts. Therefore, the conditional probability \(P(King|Heart) = 1/13\).
Example 2: Choosing without replacement. Suppose you have 3 red, 3 blue, and 3 yellow balls in a non-transparent bag. What is the probability to pick a blue ball on the first trial? And on the second trial?
First trial: \(P(\text{blue on first})=3/9=1/3=0.33333\) and \(P(\text{not blue on first})=6/9=2/3\).
Second Trial: The probability of picking a blue ball on the second trial depends on the outcome of the first trial. There are two possible scenarios:
Scenario 1: Blue ball picked on the first trial. In this case, there are only 2 blue balls left out of a total of 8 balls. So, the probability of picking another blue ball is 2/8 = 1/4. The probability is \(P(\text{blue|blue on first}) = 1/4 = 0.25\).
Scenario 2: Non-blue ball picked on the first trial. In this case, all 3 blue balls are still left out of a total of 8 balls. This probability is \(P(\text{blue|not blue on first}) = 3/8 = 0.375\).
To get the overall probability of picking a blue ball on the second trial, we need to consider both scenarios and their respective probabilities.
The probability of Scenario 1 (picking a blue ball on the first trial) is 1/3. The probability of Scenario 2 (picking a non-blue ball on the first trial) is (1 - 1/3)=2/3. Therefore, the overall probability of picking a blue ball on the second trial is:
\[
\begin{aligned}
P(\text{blue on second trial}) &= P(\text{blue|blue on first}) * P(\text{blue on first}) \\
&\quad + P(\text{blue|not blue on first}) * P(\text{not blue on first}).
\end{aligned}
\]
\(P(\text{blue on second trial}) = (1/4 * 1/3) + (3/8 * 2/3) = 1/3 .\) The probability of picking a blue ball on the second trial is also 1/3, because of the symmetry of the problem.
Law of Total Probability
The law of total probability extends the concept of conditional probability to situations where the event of interest can occur under multiple different, mutually exclusive scenarios. It provides a way to calculate the probability of an event based on a partition of the sample space into disjoint subsets. It is formulated as follows: Let \(B_1, B_2, ..., B_n\) be mutually exclusive and collectively exhaustive events, meaning no two events can occur at the same time, and one of these events must occur. Then, the probability of an event \(A\) which accounts for the dependence of \(A\) on all possible subsets can be expressed as:
This equation sums the probabilities of \(A\) occurring in each scenario \(B_i\), weighted by the probability of each scenario \(B_i\) occurring. This formula is useful when \(A\) can be influenced by various factors (represented by \(B_i\)) whose probabilities are known.
In the last example, we applied this law to take into account the probabilities corresponding to all scenarios that cover drawing a blue ball the second time: \(P(\text{blue on second trial}) = (1/4 * 1/3) + (3/8 * 2/3) = 1/3\). We splitted the problem into two mutually exclusive scenarios (blue ball picked first or not), which helped to calculate the overall probability using the law of total probability.
9.4 Bayes’ Theorem
We can now introduce the central equation which enables dealing with conditional probabilities (and which is the foundation of Bayesian statistics): the Bayes’ theorem, or, the Bayes’ rule.
Bayes’ theorem is a fundamental concept that describes how to update the probability of an event based on new evidence. It is stated as:
\(P(A \mid B) = \frac{P(A) \cdot P(B \mid A)}{P(B)}\)
where:
\(P(A|B)\): The posterior probability of event A happening given that event B has occurred.
\(P(B|A)\): The likelihood of observing B given that A has occurred. It provides the information how probable is the observed data, based on a specific hypothesis.
\(P(A)\): The prior probability of event A, representing our initial belief before considering the new evidence B.
\(P(B)\): The evidence or marginal likelihood of event B.
Example: Consider a disease test that is 99% accurate, meaning it correctly identifies 99% of people with the disease and 99% of people without the disease. Suppose 1% of the population has this disease. If a person tests positive, what’s the actual probability they have the disease?
Let “Disease” be the event of having the disease, and “Positive” be the event of testing positive.
We know the prior probability: \(P(\text{Disease}) = 0.01\) (1% of the population has the disease).
We also know the likelihood: \(P(\text{Positive|Disease}) = 0.99\) (this is the medical test accuracy). It is the probability of getting a positive test given that the person actually has the disease. This is also referred to as the sensitivity, or true positive rate of the medical test.
We need to calculate: \(P(\text{Disease|Positive})\), which we do using Bayes’ theorem:
So, even with a 99% accurate test, the probability of having the disease given a positive result is only 50% because the disease is rare in the population.
9.5 Estimating the parameters in probabilistic models
The likelihood term in Bayes’ theorem \(P(B|A)\) refers to the probability of observing the data (evidence) given a specific hypotheis or model (in our example above, the likelihood was 0.99, the probability the test is positive when the person actually has the desease). The likelihood in Bayes’ theorem quantifies how well the hypopthesis explains the observed data. Higher likelihood suggests that the hypothesis is more likely to be true, given the data.
Likelihood Estimation: Likelihood is a measure of how well a particular statistical model (with its given parameters) explains observed data. It focuses on parameter estimation based on the data we have seen. For example, suppose you flip a coin ten times and get seven heads. The likelihood of observing this data (seven heads out of ten flips) depends on the probability of heads for that coin. The likelihood would be higher for a coin biased towards heads (e.g., P(Heads) = 0.7) compared to a fair coin (P(Heads) = 0.5). The basic idea in likelihood estimation is to find parameter values that maximize the likelihood function. When we deal with more data, the likelihood of observing that data can be modeled using a specific probability distribution. Our hypothesis might be that the Gaussian (normal) distribution best fits the data. Then the likelihood function\(L(\theta; X)\) is defined by two parameters: \(\mu\) - the mean of the Gaussian distribution, and \(\sigma\) - the standard deviation of the distribution. The Gaussian likelihood is \(L(\mu, \sigma^2; X) = \prod_{i=1}^n \frac{1}{\sqrt{2\pi \sigma^2}} \exp\left(-\frac{(x^{(i)} - \mu)^2}{2\sigma^2}\right)\), where \(x^{(i)}\) corresponds to each data sample. The likelihood function is the product of the probability density functions evaluated at each \(x^{(i)}\), indicating how likely it is to observe the data \(X\) given the parameters \(\mu\) (mean) and \(\sigma^2\) (standard deviation).
The goal of likelihood estimation is to find the values of \(\mu\) and \(\sigma\) that maximize the probability of observing the data we have. This means finding the Gaussian distribution that best fits the data points. Two approaches of finding the parameters are described below.
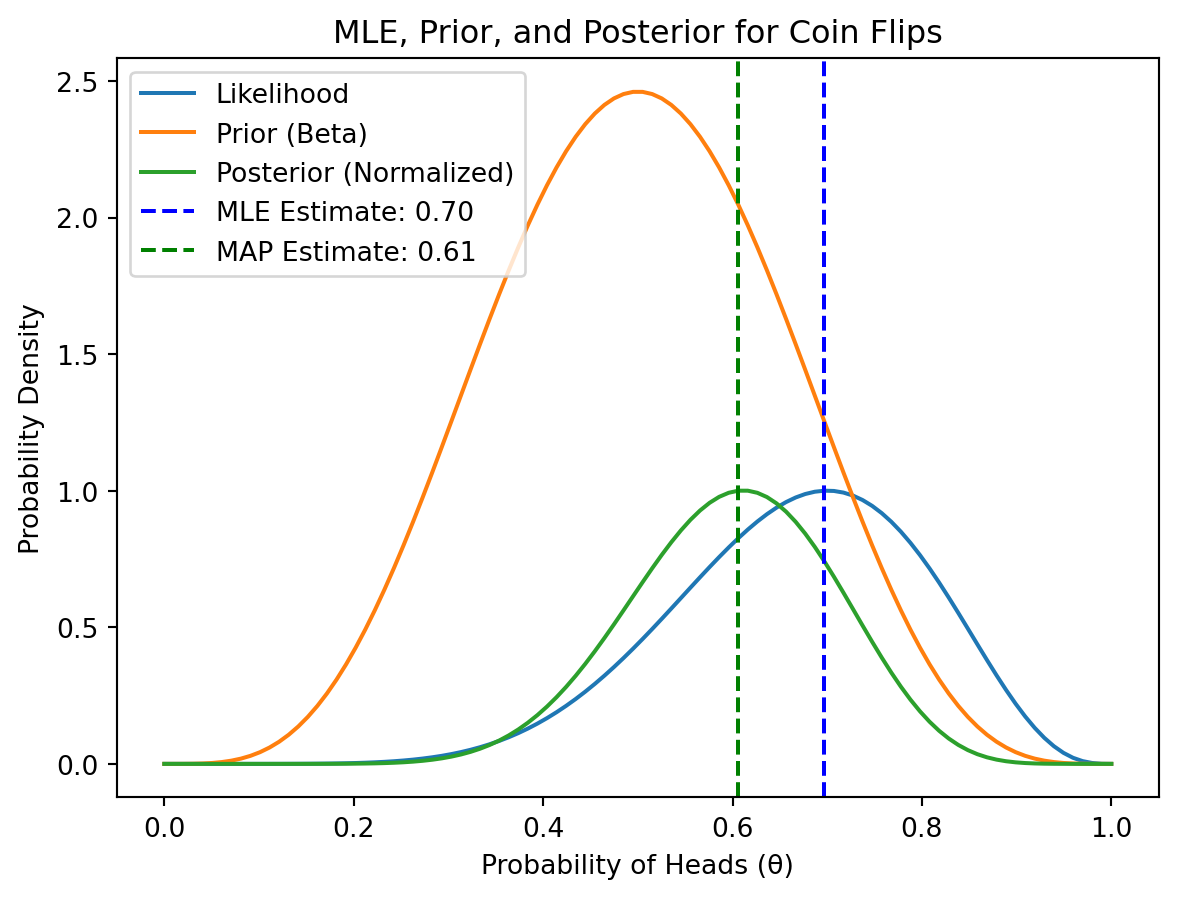
Maximum Likelihood Estimation (MLE): MLE is a method for finding the parameter values that maximize the likelihood function. It aims to find the parameters that make the observed data most probable under the assumed statistical model. MLE can be thought of as maximizing the posterior probability using a uniform prior, meaning it doesn’t incorporate prior beliefs about the parameters. Continuing the coin flip example, MLE would be used to estimate the probability of heads (the parameter of the Bernoulli distribution) that maximizes the likelihood of observing seven heads out of ten flips. In this case, the MLE estimate would be 0.7 (the observed proportion of heads). Formally, the MLE estimate of parameters \(\theta\) is given by:
where: \(\theta_{\text{MLE}}\) represents the MLE estimate of the parameters, \(X\) is the observed data. We denote with \(L(\theta; X)\) the likelihood function, which is equivalent to the probability of observing the data X given the parameters \(\theta\): \(P(X|\theta)\). We aim to find the values for the parameter \(\theta\) that make the observed data \(X\) the most likely to have occured according to the assumed probability model (probability distribution).
Often, instead of maximizing the likelihood, it is mathematically easier to minimize the negative logarithm of the likelihood, which is known as negative log-likelihood. The negative log-likelihood is simply a transformation of the likelihood function. The corresponding equation is:
Back to our coin flip example: We observe 10 coin flips with 7 heads and 3 tails.
The likelihood of observing this data given a particular value of p is calculated as: \(L(p; X) = p⁷(1-p)³\). This corresponds to a Bernoulli distribution, with parameters \(a=7\) (7 trials with heads) and \(b=3\) (3 trials with tails). Here \(p\) is the prior probability of observing heads, and we assume it is 0.5, corresponding to a fair coin.
Negative Log-Likelihood: The negative log-likelihood is then: \(NLL(p; X) = -7log(p) - 3log(1-p)\).
We now avoid working with products of variables, which is convenient, because products of probabilities could result in very small numbers, approaching zero. This could cause numerical problems. To find the maximum likelihood estimate of p, we could either maximize the likelihood function or minimize the negative log-likelihood function. Both approaches would lead to the same estimate of p.
Maximum A Posteriori (MAP) Estimation: MAP estimation builds upon MLE and incorporates prior knowledge about the parameters using Bayesian principles. It seeks the parameter values that maximize the posterior probability, balancing the information from the observed data (likelihood) with our prior beliefs. For example, suppose you have a prior belief that the coin is fair. In this case, MAP estimation would incorporate this prior information. Using a suitable prior distribution that reflects this belief, MAP would estimate a probability of heads that’s somewhere between the MLE estimate (0.7) and the prior belief (slightly less than 0.5), depending on the strength of the prior and the observed data. Formally, the MAP estimate of parameters \(\theta\) is:
\(\theta_{\text{MAP}}\) represents the MAP estimate of the parameters.
\(P(\theta|X)\) is the posterior probability of the parameters given the data. \(P(X|\theta)\) is the likelihood. The likelihood term provides the informaiton of how probable is the observed data, given a specific hypothesis and its parameters. \(P(\theta)\) is the prior probability of the parameters. The prior probability term allows us to inject our prior knowledge or assumptions about the parameters into the estimation process. \(P(X)\) is the evidence. This term is often ignored during optimization as it is a constant with respect to the parameters.
Code
import numpy as npimport matplotlib.pyplot as pltfrom scipy.stats import beta# Generate synthetic coin flip data (7 heads, 3 tails)np.random.seed(42) # For reproducibilitynum_flips =10prob_heads =0.7# True probability of heads (for data generation only)#flip_data = np.random.binomial(1, prob_heads, num_flips)flip_data = [ 1, 1 , 1 ,1 ,1, 1, 1, 0, 0 ,0] #manually written heads and tailsprint(flip_data)# Function to calculate the likelihooddef likelihood(theta, data): num_heads = np.sum(data) num_tails =len(data) - num_headsreturn theta**num_heads * (1- theta)**num_tails# Range of theta (probability of heads) valuestheta_range = np.linspace(0, 1, 100)# Calculate likelihood for each theta likelihood_values = [likelihood(t, flip_data) for t in theta_range]# Normalize the likelihoodlikelihood_values = likelihood_values / np.max(likelihood_values)# Find the MLE estimatemle_estimate = theta_range[np.argmax(likelihood_values)]# Define a Beta prior distributionalpha =5# Prior parameter for heads (considering a fair coin) beta_param =5# Prior parameter for tails (considering a fair coin)# alpha and beta play the roles of a "prior number of heads" and "prior number of tails" (pseudotrials), and alpha+beta can be interpreted as an effective sample size. If the coin is fair, for 10 trials we have five heads (alpha=5) and five tails (beta=5).prior_distribution = beta(alpha, beta_param)# Calculate the posterior (unnormalized)posterior_values = [prior_distribution.pdf(t) * likelihood(t, flip_data) for t in theta_range]# Normalize the posteriorposterior_values = posterior_values / np.max(posterior_values)# Find the MAP estimatemap_estimate = theta_range[np.argmax(posterior_values)]# Plotplt.plot(theta_range, likelihood_values, label="Likelihood")plt.plot(theta_range, prior_distribution.pdf(theta_range), label="Prior (Beta)")plt.plot(theta_range, posterior_values, label="Posterior (Normalized)")plt.title("MLE, Prior, and Posterior for Coin Flips")plt.xlabel("Probability of Heads (θ)")plt.ylabel("Probability Density")plt.axvline(x=mle_estimate, color='b', linestyle='--', label=f"MLE Estimate: {mle_estimate:.2f}")plt.axvline(x=map_estimate, color='g', linestyle='--', label=f"MAP Estimate: {map_estimate:.2f}")plt.legend()plt.show()
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0]
Figure 9.1: Plots of the maximum parameter estimates resulting from MLE and MAP for the coin flip example (10 fair coin flips with 7 heads and 3 tails). Note that the MAP estimate is biased towards the probability for fair coin (it is centered at 0.61, not at 0.7 like the MLE), because it incorporates the prior belief of having a fair coin. The MLE reflects purely the observed data.
9.6 Generative models
While discriminative models directly learn a decision boundary to separate classes, generative models learn the underlying probability distribution of the data within each class. They aim to understand how the data is generated, and what is the data’s underlying distribution across classes. For the class of generative models, some representative machine learning models are Naive Bayes, and Dynamic Causal Modeling (DCM). In deep learning, some generative models are Generative Adversarial Networks (GANs), and diffusion-based models.
To understand the distribution of the data across different classes, generative models (in particular classifiers) learn the joint probability distribution \(P(X, Y)\), which represents the probability of observing both features \(X\) and their corresponding labels \(Y\). Here, \(X\) and \(Y\) denote the features (inputs) and the labels (outputs) of the whole dataset of training data, i.e. \(\{x^{(i)},y^{(i)}\}\) for \(i = 1 … N\), respectively.
In generative models, we estimate two key components:
\(P(X | Y)\): The likelihood of observing features \(X\) given a particular class label \(Y\).
\(P(Y)\): The prior probability of each class label \(Y\).
Once these probabilities are learned, generative models utilize Bayes’ Theorem to calculate the posterior probability \(P(Y|X)\), which is the probability of having a class label \(Y\) given the observed features \(X\). This probability is then used to make predictions. The class label that corresponds to the highest posterior probability is assigned to a new data point, depending on its features.
This is very different from how discriminative models work. Discriminative models, in contrast to generative models, directly learn the decision boundary that best separates different classes without explicitly modeling the data generation process. Their primary focus is on learning a function that maps input features \(X\) to the most likely class label \(Y\), directly estimating the conditional probability \(P(Y|X)\). They find the features that display the most significant differences between data from various classes. For example, logistic regression models the probability of a binary outcome (e.g., 0 or 1) using a sigmoid function. It learns the weights of the features that contribute to predicting the outcome. Then, new data points can be classified based on their feature values.
An intutitive example
We will use the analogy of classifying images as “dogs” or “cats” to illustrate the difference between discriminative and generative models:
1. Discriminative models
Learning. Learn the boundary that separates dog images from cat images without modeling the individual distributions.
In logistic regression, this boundary is represented by a hyperplane in the feature space. The hyperplane’s position and orientation are determined by the model parameters (weights \(w_j\)), learned during training. These weights quantify the contribution of each feature to the classification decision. For example, if “ear pointiness” is a feature, a positive weight associated with this feature indicates that pointy ears contribute to classifying an image as a cat. A negative weight suggests the opposite.
Logistic regression doesn’t attempt to model the individual distributions of features within each class (cat or dog). It directly focuses on learning the optimal boundary that separates them.
Inference. Given a new image, determine on which side of the boundary it falls to classify it as a dog or cat.
When presented with a new image, its features are extracted and combined with the learned weights to produce a linear combination. This combination is then passed through a sigmoid function, which outputs a probability between 0 and 1. If the probability exceeds a threshold, the image is classified as a cat; otherwise, it is classified as a dog. Thus, logistic regression (discriminative model) learns a discriminative boundary between classes by adjusting the weights of features.
2. Generative Model
Learning - prior probabilities.
In practice, prior probabilities are estimated from the frequency of each class in the training data. For example, if 70% of the images in the training set are dogs and 30% are cats, the prior probability of an image being a dog \(P(Dog)\) would be 0.7, and the prior probability of being a cat \(P(Cat)\) would be 0.3.
Learning - likelihoods. Calculate probabilities of features (like pointy ears) occurring in different classes, (dogs vs. cats).
The generative approach first examines the relationship between features and classes by calculating the likelihood of observing specific feature values given a particular class. It determines the probability of pointy ears given that the image is of a cat \(P(pointy ears | Cat)\) and the probability of pointy ears given that the image is of a dog \(P(pointy ears | Dog)\). By analyzing these patterns across multiple features, Naive Bayes builds a probabilistic model of how features are distributed within each class. These probabilities correspond to likelihoods for each class, and are important parameters in the Naive Bayes model. They capture how likely it is to observe a specific feature value within a particular class. A
The likelihoods, together with the prior probabilities of each class (e.g., the proportion of dog images vs. cat images in the training set), are used to calculate the posterior probability.
Inference. Given a new image, calculate the probability of it being in a particular class (a cat or dog) based on the observed features.
When classifying a new image, the generative model combines the prior probabilities and likelihoods using Bayes’ Theorem to calculate the posterior probabilities for each class. For example, it calculates the probability of the image being a cat given its features \(P(Cat | observed features)\) and the probability of it being a dog \(P(Dog | observed features)\). The image is assigned to the class that, based on the available evidence (features(priors) and likelihoods), is most likely to be true. This is the class corresponding to the higher posterior probability. Generative models learn the probability distributions of features within each class and use these distributions, along with Bayes’ Theorem, to calculate the posterior probabilities for classification.
The following can be said about the two approaches if we try to compare them to our reasoning:
Generative models correspond to the approach of someone who studies dogs and cats, aiming to understand them so well that they could draw a typical representative of each. Discriminative models correspond to the approach of someone who focuses on the key differences between dogs and cats, so they can quickly point out those differences, without really understanding each animal.
9.7 Naive Bayes
Naive Bayes is a generative model used in supervised machine learning for classification tasks. Instead of directly learning the decision boundary between classes, it learns the probability distribution of data within each class. It operates under the “naive” assumption that all features are conditionally independent of one another given the class label. This means that knowing the value of one feature doesn’t provide any information about the value of another feature, as long as you already know the class label. For example, Naive Bayes would assume that knowing an animal has pointy ears doesn’t tell us anything about whether its fur is striped or solid, as long as we know it is a cat. This assumption simplifies calculations significantly because it allows the model to calculate the probability of observing a set of features by simply multiplying the individual probabilities of each feature given the class (see Joint probability for independent events). Although this assumption rarely holds perfectly in real-world data, it simplifies computations and often leads to robust results in practice.
Naive Bayes uses Bayes’ Theorem to predict the class of a new data point. As we saw, Bayes’ Theorem relates the conditional probability of an event \(A\) given event \(B\) to the probability of event \(B\) given event \(A\). In Naive Bayes, it is used to calculate the probability of a class label given the observed features:
\(P(class | features)\) is the posterior probability, the probability of the data point belonging to the class given its features. This is what the model wants to predict.
\(P(features | class)\) is the likelihood, the probability of observing those features given that the data point belongs to that class.
\(P(class)\) is the prior probability of that class, the probability of a randomly selected data point belonging to that class. This is usually calculated based on the distribution of classes in the training set.
\(P(features)\) is the evidence, the probability of observing those features regardless of the class. This term is often ignored in calculations as it is a constant for all classes and does not affect the relative probabilities.
During the training phase, the model estimates the prior probabilities and likelihoods based on the training data. Then, in the testing phase, for each new data point, it calculates the posterior probability for each class using the learned probabilities and Bayes’ Theorem. Finally, it assigns the data point to the class with the highest posterior probability.
Naive Bayes classifier
Naive Bayes typically uses maximum likelihood estimation (MLE) to determine the values of the model parameters (prior probabilities and likelihoods) (it is also possible to use MAP to incorporate prior knowledge).
Types of Naive Bayes
There are different types of Naive Bayes classifiers, each suited for specific data types:
Bernoulli Naive Bayes: This classifier is employed for binary data, where features are represented as present or absent (1 or 0). It is well-suited for binary/boolean feature sets, where the frequency of a feature is not important, but rather its presence or absence.
Multinomial Naive Bayes: This classifier is suitable for count data, such as word counts in text documents. It is frequently used for tasks like spam detection, where the frequency of words or terms plays a crucial role in classification.
Gaussian Naive Bayes: This classifier is utilized for continuous data, and assumes that features follow a Gaussian (normal) distribution. This type is appropriate for datasets with numerical features.
Advantages and disadvantages
Model type
Advantages
Disadvantages
Generative
Can generate new data samples
Computationally expensive
Generative
Provides a complete understanding of the data distribution.
Strong assumptions about feature independence
Generative
Robust with limited data.
Discriminative
More accurate and efficient for classification.
Cannot generate data samples
Discriminative
Weaker assumptions about feature independence.
Less interpretable
Discriminative
Well-suited for high-dimensional data
Performance depends on the choice of features
Example:
We will classify emails as “Spam” or “Not Spam” based on the presence of the words “offer” and “win”, using Naive Bayes. So, our features are “offer” and “win”, and the labels are “Spam” or “Not Spam” . The dataset looks like this:
Email
Word: “offer”
Word: “win”
Class
1
Yes
Yes
Spam
2
Yes
No
Not Spam
3
No
Yes
Spam
4
No
No
Not Spam
First, we calculate prior probabilites:
\(P(\text{Spam}) = 0.5\). This is because 2 out of 4 emails are labelled as “Spam”.
\(P(\text{Not Spam}) = 0.5\). This is because 2 out of 4 emails are labelled as “Not Spam”.
Then we have to calculate the likelihoods (how likely it is to observe specific words in an email given that it is spam or not spam). THis corresponds to how likely is to observe a feature (word) in a given class (“Spam” or “Not Spam”.):
The goal is to determine which class (“Spam” or “Not Spam”) is more probable given that we observe both the words “offer” and “win” in the email. We want to calculate:
\(P(Spam | offer, win)\): The probability that the email is spam given the presence of “offer” and “win.”
\(P(Not Spam | offer, win)\): The probability that the email is not spam given the presence of “offer” and “win.”
We now apply the Bayes’ Theorem to calculate these probabilities:
The “naive” assumption in Naive Bayes is that the words “offer” and “win” are conditionally independent given the class (“Spam” or “Not Spam”). This assumption simplifies the calculation. Using the independence assumption, we can rewrite the likelihood terms as joint probabilities (so, we rewrite them as simple products of probabilities):
\(P(offer, win | Not Spam) = P(offer | Not Spam) * P(win | Not Spam)\)
We can ignore the denominator, \(P(offer, win)\), as it is a normalization factor and does not affect which class has a higher probability. Therefore we have: