The explicit solution for linear regression with normal equation from Section 2.3.2.2 can compute the best fitting model for given datapoints. However, this method does not work in practice for larger input datasets, since the method involves matrix multiplication and inversion. The runtime for these operations is approximately cubic in size of the matrix. As a rule of thumb, the process is too time-consuming or breaks for more than 20’000 features or samples. In addition, the normal equation might become numerically instable if the input features are higly correlated.
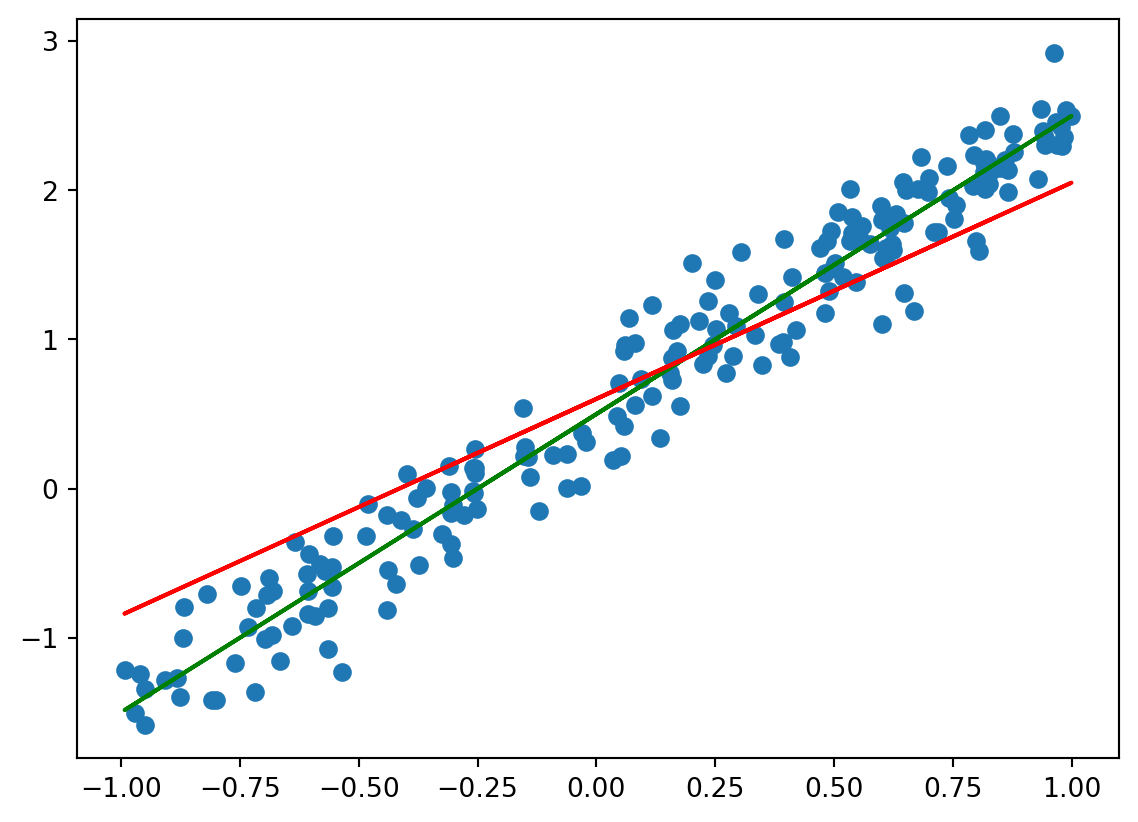
If we cannot use the normal equation to solve an instance of linear regression explicitly, we can try to find an “as good as possible” solution, i.e. values for the parameters \(\theta\) such that the corresponding model approximates an optimal model. Note that we now introduce a second level of error: First, any linear model for a given dataset will usually not fit exactly to the data, but rather have some error (the residuals). Now, in addition, we do not expect to find the optimum solution, but rather an approximation of the best solution. Hence the expected error will be even larger. For univariate linear regression, the direction of the resulting line might be “a little off”, as shown in the figure below.
Code
import numpy as npfrom matplotlib import pyplot as plt# num samplesM =200# synthetic datarng = np.random.default_rng(0xdeadbeef)x =2.* rng.random(size=M) -1.noise = rng.normal(loc=0., scale=.25, size=M)theta_0 =.5theta_1 =2.y = theta_0 + (theta_1 * x) + noiseplt.scatter(x, y)# do stuff in matrix formX = np.ones((M, 2))X[:, 1] = x# initial theta estimatetheta = np.zeros(2)N_iter =7learning_rate =.5for i inrange(N_iter):# compute gradient g = np.zeros(2)for j inrange(M): xj = X[j, :] y_pred = xj @ theta g += (1/ M) * (y[j] - y_pred) * xj theta += learning_rate * gy_pred = X @ thetaplt.plot(x, theta_0 + (theta_1 * x), c='g')plt.plot(x, y_pred, c='r')plt.show()
Figure 3.1: Application of gradient descent. Input: points randomly distributed around green line. Red line: Output of gradient descent.
A common approach is to start with some initial values for the parameters \(\theta\) (e.g. random values), and then iteratively adapt \(\theta\) “a little bit” such that the corresponding model better fits the given data. The update step is repeated until the process converges, e.g. if the parameters do not change anymore.
Note that once the process has finished and we found our solution \(\hat{\theta}\), we can as usual compute for every input \(x\) a corresponding output \(\hat{y} = h_{\hat{\theta}}(x)\). To determine how good the data “fits the given data”, we can use the cost function \(J(\theta) = \frac{1}{2M} \sum_{m=1}^M (y^{(m)} - \hat{y}^{(m)})^2\) from Equation 2.1.
3.2 Gradient Descent Algorithm
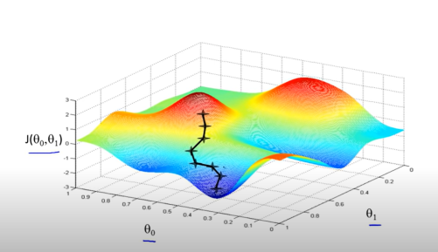
One of the most well-known algorithms to solve this task is Gradient Descent. Figure 3.2 shows the core idea for a function where we have two paramaters that we need to find, \(\theta_0\) and \(\theta_1\). The image shows for each parameter combination the corresponding cost \(J(\theta_0, \theta_1)\) (note that the image shows the cost function of a non-linear model; for a linear model, the cost function would be convex).
Figure 3.2: Illustration of Gradient Descent: x-axis and y-axis are values of parameters \(\theta_0\) and \(\theta_1\), respectively, and the z-axis shows for each combination of \(\theta_0\) and \(\theta_1\) the cost \(J(\theta_0, \theta_1)\) of the corresponding model. Starting with initial values for \(\theta_0\) and \(\theta_1\), it follows a decending path until it ends up with good values for \(\theta_0\) and \(\theta_1\).
For instance, for parameters \(\theta_0 = 0.7\) and \(\theta_1 = 0.5\), we have very large costs J (indicated in red), which means that the corresponding model for these parameters does not fit well with the data, whereas \(\theta_0 = 0.4\) and \(\theta_1 = 0.1\) has a lower cost (indicated in blue).
Note that gradient descent is a very generic algorithm that can be used for optimizing many machine learning models. Moreover, it can be used not just for convex cost functions (like in linear regression), but also for the non-convex cost functions that arise, for instance, in training neural networks. The image above shows a non-convex example.
Gradient Descent uses the gradient (i.e., partial derivaties) to determine in which direction the parameters should be adapted in order to reduce the cost. The gradient gives the direction of steepest increase, and by moving opposite the gradient, we cause the function to decrease in value.
The generic algorithm for gradient descent for \(n\) parameters \(\theta_0, ... \theta_n\) is as follows:
Initialize: \(\theta_0, ... \theta_n\)
Repeat until convergence: \[\text{Update} \: \theta_j = \theta_j - \alpha \frac{\partial}{\partial \theta_j}J(\theta)\quad \; \forall j = 0, ... n \tag{3.1}\]
Here, \(\alpha\) is the Learning Rate, which determines how far we step each time. We will discuss learning rates in Section 3.4. For now, you can just ignore \(\alpha\).) Since we want to reduce the cost, we step opposite the direction of the gradient (i.e., \(-\alpha \frac{\partial}{\partial \theta_j} J(\theta)\)).
Note that the gradient descent algorithm in its generic form can be applied to any learning task where we have a differentiable cost function and need to find proper parameters \(\theta\). We will see later that it can be used also, for instance, for optimizing neural networks.
3.3 Gradient Descent for Univariate Linear Regression
We now show how to use gradient descent for univariate linear regression. For this, we calculate partial derivatives of \(J\) for \(\theta_0\) and \(\theta_1\) and plug them into the algorithm shown in Equation 3.1.
Recall that in univariate linear regression, we are given \(M\) samples \((x^{(m)}, y^{(m)})\) that we use to fit our linear model, and that each input \(x^{(m)}\) is a scalar value for which we are given an expected output \(y^{(m)}\). Our goal is to find parameters \(\theta_0\) and \(\theta_1\) that minimize the cost function \(J(𝜃_0,𝜃_1)=\frac{1}{2 M} \sum_{𝑚=1}^𝑀(𝑦^{(m)} − h_{\theta} (x^{(m)}))^2\).
Thus, we start with some initial values of \(\theta_0\) and \(\theta_1\), e.g. random values, in Step 1. Then we adapt in each iteration in Step 2 the values of both parameters “a little bit in the proper direction”. The sum in both update formulas basically computes for each sample \((x^{(m)}, y^{(m)})\) the distance between the expected value \(y^{(m)})\) and the current prediction of our model \(h_{\theta}(x^{(m)})\), and updates the parameters \(\theta_0\) and \(\theta_1\) accordingly.
Note that \(\theta_0\) and \(\theta_1\) are updated simultaneously. One common error when implementing gradient descent is to first update \(\theta_0\), and then use this updated value when computing \(h_{\theta}(x^{(m)})\) for the update of \(\theta_1\). Instead, you have to use the old value of \(\theta_0\) here.
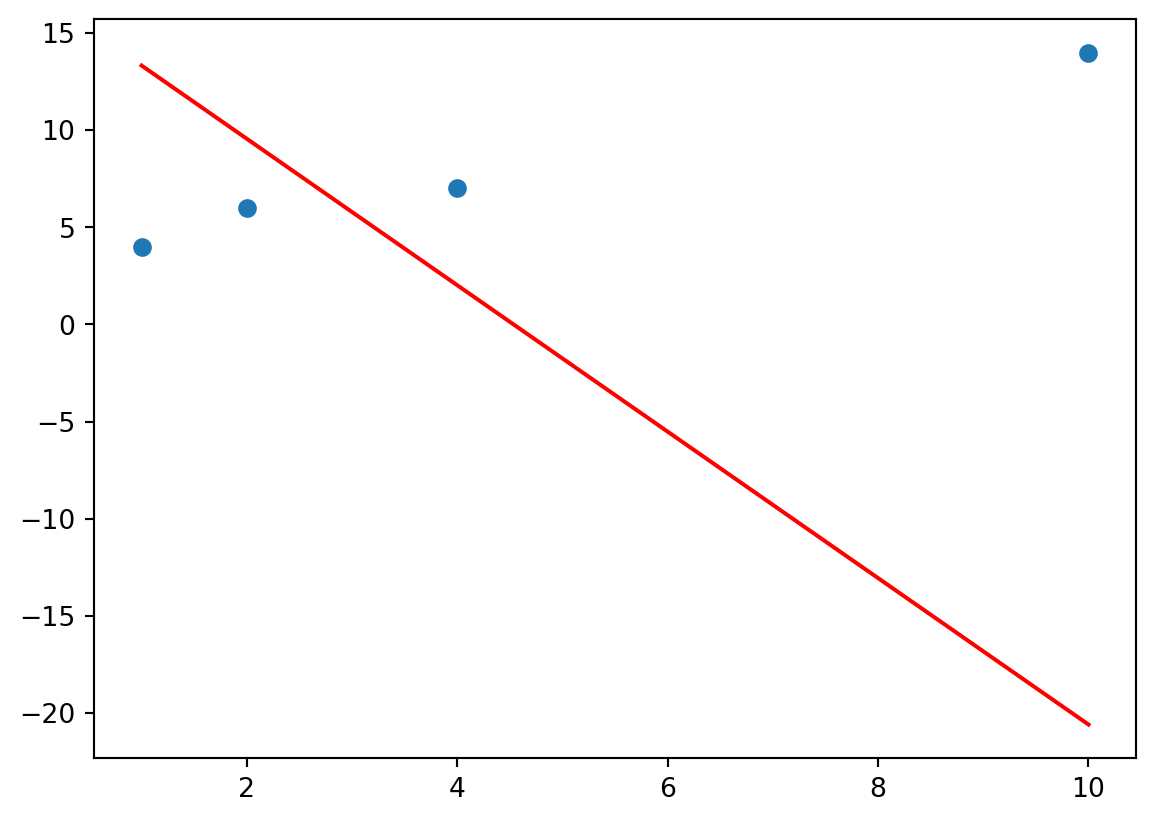
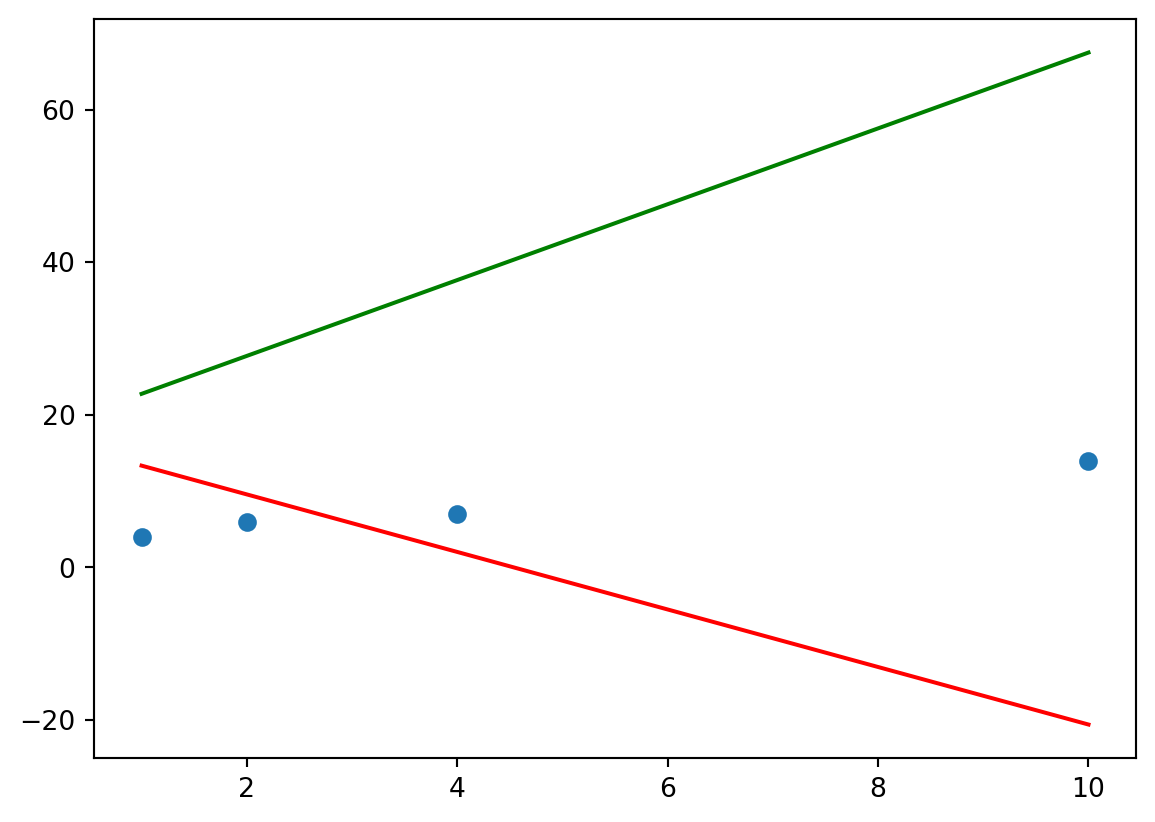
Example. Assume we are given a set of four samples (1,4), (2,6), (4,7) and (10,14) for an univariate linear regression problem. We initialize the two parameters \(\theta_0\) and \(\theta_1\) randomly, e.g. with \(\theta_0 = 17.1\) and \(\theta_1 = -3.77\). The following plot shows the four samples and the current solution, which is obviously far off.
Code
import numpy as npfrom matplotlib import pyplot as plt# num samplesM =4# synthetic datarng = np.random.default_rng(0xdeadbeef)x = [1,2,4,10]y = [4,6,7,14]theta_0 =17.1theta_1 =-3.77plt.scatter(x, y)# do stuff in matrix formX = np.ones((M, 2))X[:, 1] = xtheta = (theta_0, theta_1)y_pred = X @ thetaprint("predicted values:", y_pred)plt.plot(x, y_pred, c='r')plt.show()
predicted values: [ 13.33 9.56 2.02 -20.6 ]
Figure 3.3: Simple Example of Gradient Descent. Dots are given samples, blue line shows the initial linear model.
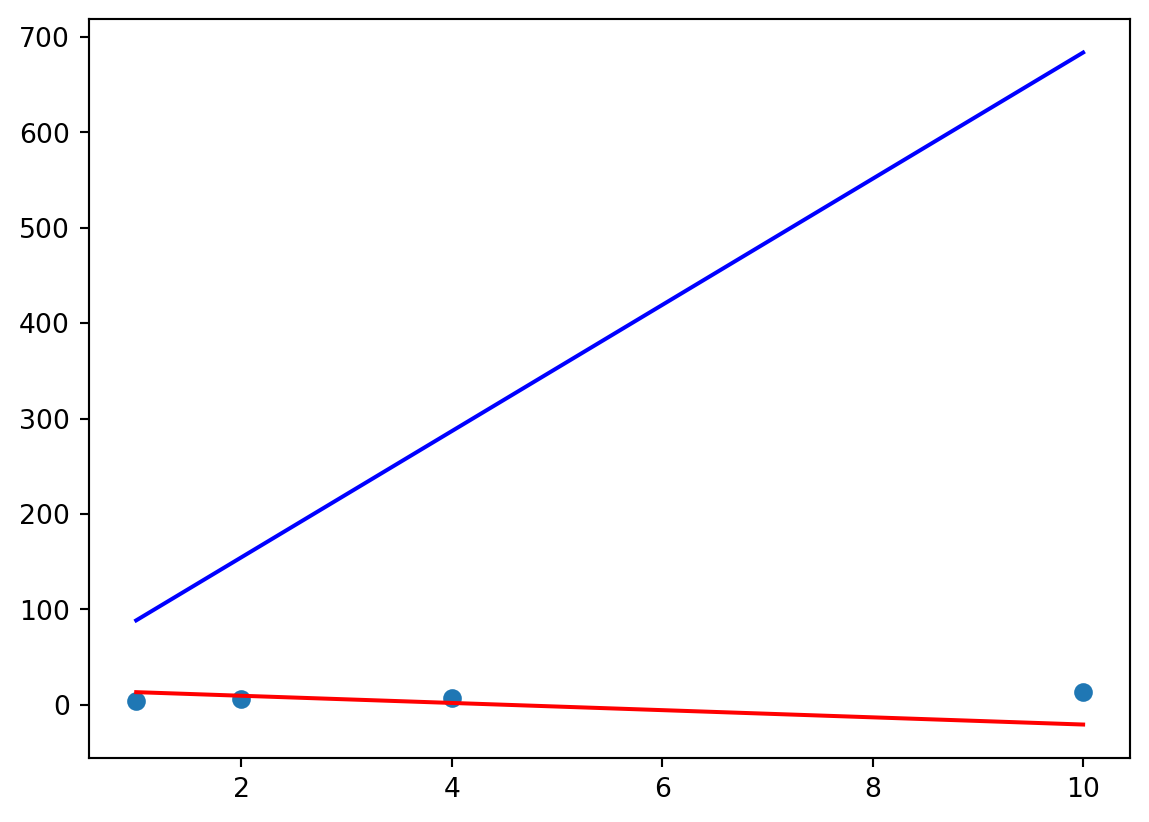
Now we make one step of gradient descent according to Equation 5.3. We use a learning rate \(\alpha = 0.8\). We first compute the new value of \(\theta_0\): \[\theta_0 = 17.1 - 0.8 * \frac14 ((13.33-4) + (9.56-6) + (2.02-7) \]\[ + (-20.6-14)) = 22.44\] Next, we compute the new value of \(\theta_1\). Note that we use the old value of \(\theta_0\) here: \[\theta_1 = -3.77 - 0.8 * \frac14 ((13.33-4) * 1 + (9.56-6) * 2 + (2.02-7) * 4 \]\[ + (-20.6-14)* 10) = 66.12\]
Code
import numpy as npfrom matplotlib import pyplot as plt# num samplesM =4# synthetic datarng = np.random.default_rng(0xdeadbeef)x = [1,2,4,10]y = [4,6,7,14]theta_0 =17.1theta_1 =-3.77plt.scatter(x, y)# do stuff in matrix formX = np.ones((M, 2))X[:, 1] = xtheta = (theta_0, theta_1)y_pred = X @ thetaplt.plot(x, y_pred, c='r')theta_0_new =22.44theta_1_new =66.12theta_new = (theta_0_new, theta_1_new)y_pred_new = X @ theta_newprint("new predicted values:", y_pred_new)plt.plot(x, y_pred_new, c='b')plt.show()
new predicted values: [ 88.56 154.68 286.92 683.64]
Figure 3.4: Updated model with learning rate 0.8. Red line shows the initial linear model, blue line the updated model.
We see that the new model is even worse and does not fit well with our samples. This might have been due to the large learning rate. If we would use a learning rate of, say, \(\alpha = 0.1\) instead, we would obtain new values \(\theta_0 = 17.77\) and \(\theta_1 = 4.97\), which yields the following chart:
Code
import numpy as npfrom matplotlib import pyplot as plt# num samplesM =4# synthetic datarng = np.random.default_rng(0xdeadbeef)x = [1,2,4,10]y = [4,6,7,14]theta_0 =17.1theta_1 =-3.77plt.scatter(x, y)# do stuff in matrix formX = np.ones((M, 2))X[:, 1] = xtheta = (theta_0, theta_1)y_pred = X @ thetaplt.plot(x, y_pred, c='r')theta_0_new =17.77theta_1_new =4.97theta_new = (theta_0_new, theta_1_new)y_pred_new = X @ theta_newprint("new predicted values:", y_pred_new)plt.plot(x, y_pred_new, c='g')plt.show()
new predicted values: [22.74 27.71 37.65 67.47]
Figure 3.5: Updated model with learning rate 0.1. Red line shows the initial linear model, green line the updated model.
3.4 Learning Rate
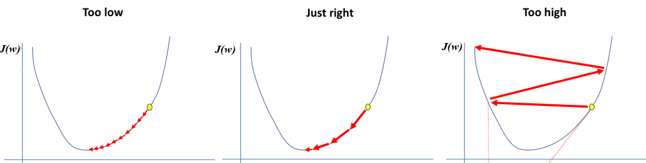
The partial derivatives in gradient descent determine in which direction we need to adapt the parameters \(\theta\) in order to reduce the cost function \(J\). The larger the magnitude of the gradient, the steeper the descent, and the more we change the values of \(\theta\) in a single step. Unfortunately, we can sometimes “overstep” if the gradient is too large. This is shown in Figure 3.6 on the right hand side (note that this is NOT a true image for linear regression, but rather an illustrative example): Starting at the yellow point, the gradient might be so large that we “jump” over the minimum and end up on the left side of the curve and thus miss the minimum. In the worst case, we might even move further away from the minimum with each step, as illustrated in the Figure. To resolve this, we introduced in the gradient descent algorithm (see Equation 3.1) the Learning Rate\(\alpha\), which allows us to scale the step width up and down. Note that if we scale down the step width too much, the algorithm will converge very slowly, as shown in Figure Figure 3.6 on the left side.
Figure 3.6: Illustration of very small (left), good (center) and very large step width of the gradient descent algorithm
3.4.1 Learning Rate Optimization
As a rule of thumb, we want to have a larger learning rate at the beginning of the algorithm (the algorithm moves fast towards the minimum), while the learning rate should be smaller towards the end, where we want to approximate the minimum as good as possible. One way to achieve this is to use a fixed Decay Rate to reduce the learning rate in each step: Starting with an initial value \(\alpha_0 = 0.1\), we compute the learning rate for each step as \(\alpha_t = \frac{1}{1 + decay\_rate * t}\alpha_0\) where \(t=1, 2, \ldots\) is the iteration of the gradient descent loop.
Other methods such as Adam or Adagrad are more involved and use, for instance, the values of the gradients from one or more previous steps to compute the update of \(\alpha\).
A detailed analysis of how to compute the partical derivatives is available at https://medium.com/swlh/the-math-of-machine-learning-i-gradient-descent-with-univariate-linear-regression-2afbfb556131↩︎