In this chapter, we will study how machine learning models can predict a single value, give some input features. A typical application would be to predict the price of a car, give its features such as brand, mileage, color, extras.
2.1 A Motivating Example
We first look at a real-world example, where we want to predict life satisfaction in relation from the gross domestic product (GDP) for a subset of countries (each dot in the chart below is one country). The GDP basically measures the monetary value of all goods and services for end users that are produced in a country in, say, a year.
Code
import pandas as pdfrom matplotlib import pyplot as pltgdppc_col ='GDP per capita (USD)'lifesat_col ="Life satisfaction"df_full_country_stats = pd.read_csv('./datasets/country_stats.csv')df_full_country_stats.set_index('Country', inplace=True)df_country_gdp_lifesat = df_full_country_stats[['GDP per capita (USD)', 'Life satisfaction']]min_gdp =23_500max_gdp =62_500df = df_country_gdp_lifesat[(df_country_gdp_lifesat[gdppc_col] >= min_gdp) & (df_country_gdp_lifesat[gdppc_col] <= max_gdp)]k =4gdp_interest = df.loc['Canada'][gdppc_col]# makes the inline-figures in notebooks look crisper%config InlineBackend.figure_format ='svg'fig, ax = plt.subplots(figsize =(5, 3))min_life_sat =4max_life_sat =9ax.grid(axis='both', color ='lightgrey', linestyle ='-' )# for the purposes of this exercise, suppose we do not know Canada's life happiness valueall_but_canada = df.drop(['Canada'])ax.scatter(x=all_but_canada[gdppc_col], y=all_but_canada[lifesat_col])plt.axvline(x=gdp_interest, color='red')df_nbrs = all_but_canada.iloc[(all_but_canada[gdppc_col]-gdp_interest).abs().argsort()[:k]]ax.scatter(x=df_nbrs[gdppc_col], y=df_nbrs[lifesat_col], c='red')ax.set_ylim([4,9])ax.set_ylabel(lifesat_col, fontsize=12)ax.set_xlabel(gdppc_col, fontsize=12)plt.show()
Figure 2.1: Scatterplot illustrating the relationship between money and happiness
Let’s assume we do not have the life satisfaction value for certain countries, but we know their GDP. We would like to find a model which systematically leverages the available data to predict new values. This is a Regression Problem, since the target variable (life satisfaction) is a continuous numerical value. It is Univariate, as we only have one independent variable (here, the GDP).
For instance, if we want to know the estimated life statisfaction for Canada, which has a GDP of USD 45856.62, then we could estimate it manually to, say, 7.1 based on the adjacent dots (see red line in Figure 2.1).
2.2 Nearest Neighbor Regression
An obvious possibility would be to calculate the average from the \(k\) “closest” available values (Nearest Neighbors), for some value of \(k\). The intuition here is that examples (countries) with similar values for their independent variables (GDP) should typically have similar values for their dependent variables (life happiness). For example, \(k=4\) data points are selected with a GDP closest to the GDP of Canada (red points in Figure 2.1). The predicted life satisfaction is then calculated as the average of these 4 observed output values.
Exemplary implementation using pandas:
Code
gdppc_col ='GDP per capita (USD)'lifesat_col ="Life satisfaction"gdp_interest =45856.62df_full_country_stats = pd.read_csv('./datasets/country_stats.csv')df_full_country_stats.set_index('Country', inplace=True)df_country_gdp_lifesat = df_full_country_stats[['GDP per capita (USD)', 'Life satisfaction']]# for the purposes of this exercise, suppose we do not know Canada's life happiness valueall_but_canada = df_country_gdp_lifesat.drop(['Canada'])# get the k countries whose GDP is nearest to 45856.62df_nbrs = all_but_canada.iloc[(all_but_canada[gdppc_col]-gdp_interest).abs().argsort()[:k]]life_sat_mean = df_nbrs['Life satisfaction'].mean()print('Predicted life statisfaction for GDP USD {}: {}'.format(gdp_interest, life_sat_mean))
Predicted life statisfaction for GDP USD 45856.62: 7.275
There is no theoretical specification for the optimal number \(k\) of neighbours to consider. Hence, this number must be determined empirically. With a larger number, the flexibility of the model to map “local” patterns in the data decreases; on the other hand, the variance decreases and the prediction becomes more stable.
The nearest neighbor method is an example for Instance-based Learning. It makes predictions based on specific examples (instances) from the training data. To make predictions for a new instance, the algorithm calculates the similarity between the new instance and the instances in the training dataset. Commonly used similarity measures include Euclidean distance and cosine similarity. Unlike model-based machine learning paradigms that involve generalizing from the entire training dataset, instance-based learning relies on memorizing and storing individual training instances and uses them directly during the prediction phase. Instance-based learning is also called lazy-learning, because it defers the generalization step until prediction time. Instead of creating a general model during training, it waits until a new, unseen instance needs to be classified or predicted. At that point, it looks for similar instances in the training data and uses their labels or values to make predictions. Furthermore, it does not impose any particular assumptions about the underlying data distribution, making it a flexible approach suitable for various types of data. However, it also has some disadvantages:
Inference on a new data point generally requires the algorithm to consider explicitly all training data (to select the \(k\) closest points and compute the output)
It is sensitive to outliers and noise
Training samples further away than the \(k\) neighbours are ignored for inference, i.e. a significant part of the information contained in the training data is lost
2.3 Linear Regression
2.3.1 Univariate Linear Regression
In contrast to instance-based learning, in Model-based Learning the parameters of a general mathematical model (the Hypothesis) are adapted during a training phase in order to capture the general pattern of the data. The parametrised model can then make predictions for new input data.
One of the simplest cases of model-based learning is Univariate Linear Regression (also called Simple Linear Regression). Here, the output depends only on one input variable \(x\), and the hypothesis is a linear combination of two parameters \(\theta_0\) and \(\theta_1\) and the input value \(x\): \[h_{\theta_0,\theta_1}(x)=\theta_0+\theta_1 x\]\(\theta_0\) represents the intercept with the y-axis and \(\theta_1\) represents the slope of a straight line.
Given fixed parameter values for \(\theta_0\) and \(\theta_1\) and a specific value for the input \(x\), the model can predict corresponding output value: \[\hat{y}=h_{\theta_0,\theta_1}(x^{(m)})=\theta_0+\theta_1 x\]
Note that in the literature, \(\hat{y}\) is usually used for the predicted value (as computed by the model), whereas \(y\) would be used for the true value.
Coming back to our example, we can fit diverse univariate regression lines to the GDP-Happiness data from above. The actual values for \(\theta_0\) and \(\theta_1\) determine how well the line fits the data, as illustrated in Figure 2.2 with three different combinations of parameter values (blue, green and orange line).
Figure 2.2: Three different parameter combinations for a linear model attempting to fit the GDP-life statisfaction data.
2.3.2 Training a Univariate Regression Model
The training of a regression model aims at finding values for the model parameters \(\theta_0\) and \(\theta_1\) that fit best (or at least as good as possible) the available training data. The training data consists of \(𝑀\) samples of (input, expected output) values \({(𝑥^{(m)},𝑦^{(m)})}\) for \(m = 1,...M\), where \(x^{(1)}\) is the feature of the first sample (in our example, the GDP), and \(y^{(1)}\) would be the expected output for this input (e.g. the life satisfaction). Note that we use superscript with brackets to indicate the sample number. In our example above, the training data would consist of 25 samples, i.e. all dots (blue and red) in Figure 2.2.
For the training of the model, we typical start with arbitrary values for parameters \(\theta_0\) and \(\theta_1\) (e.g. just random values) and improve them over time, such that at the end we get a good model. A crucial ingredient for the training is a Loss Function, which measures the agreement of the model predictions with the expected output values on the training data. At the beginning of the training, the loss will be bad (i.e. a high value), and it should basically decrease over time. For linear regression, the Residual Sum of Squares \(RSS\) (also called Sum of Residuals or Sum of Squared Errors) is typically used: \[ℒ_{RSS}(𝜃_0,𝜃_1;\{x^{(m)},y^{(m)}\}) = \sum_{𝑚=1}^𝑀(𝑦^{(m)}−\hat{𝑦}^{(m)})^2 = \sum_{𝑚=1}^M \varepsilon_𝑚^2\]
with \(\varepsilon^{(m)} = y^{(m)} - \hat{y}^{(m)}\) the Residual of the \(m\)’th sample \((x^{(m)}, y^{(m)})\). Recall that \(\hat{y}^{(m)}\) is the predicted output of our model and \(y^{(m)}\) is the expected output for input \(x^{(m)}\), so the residual just computes the error our model makes - and the loss sums up all the (squared) errors over all samples in our training data.
The learning (training) consists of minimizing a Cost Function \(J\), which is a function of the model parameters and depends implicitly on the training data. In the simplest case, the cost function is equal to the loss function and a normalising factor for mathematical convenience: \[J(𝜃_0,𝜃_1)=\frac{1}{2 M} \sum_{𝑚=1}^𝑀(𝑦^{(m)}−\hat{𝑦}^{(m)})^2 \tag{2.1}\]
This is also called the Least Squares Approach. In general, however, the cost function can contain additional terms to increase the robustness of the model structure, such as regularisation terms, which we will discuss in later chapters.
Minimising the cost function results in specific values for the model parameters \(\theta_0\) and \(\theta_1\), which can then be used for predicting the outout for new data samples (also called Inference): \[\hat{y}=h_{\theta_0,\theta_1}(x)=\theta_0+\theta_1 x\]
2.3.2.1 Closed Form Solution for Univariate Linear Regression
In linear regression, closed-form expressions exist for the optimal model parameters. And for the univariate case (i.e., simple linear regression) the algebraic expressions are particularly accessible, and can be derived as follows:
Set the partial derivatives of the cost function with respect to the model parameters to zero: \[\frac{\partial}{\partial𝜃_0} 𝐽(𝜃_0, 𝜃_1)=0\ \ \]\[ \text{and}\ \ \]\[\frac{\partial}{\partial𝜃_1} 𝐽(𝜃_0, 𝜃_1)=0\]
Solve the equations for \(𝜃_0\) and \(𝜃_1\). Simple calculus (which we skip here, since it does not yield any insight. For the derivation, see Section 2.7) results in \[\theta_0=\mu_y-\theta_1\mu_x \ \ \]\[ \text{and} \ \ \]\[\theta_1=\frac{\sum_{m=1}^M(x^{(m)}-\mu_x)(y^{(m)}-\mu_y)}{\sum_{m=1}^M(x^{(m)}-\mu_x)^2}= \frac{\tilde{s}_{xy}}{\tilde{s}_x^2} \tag{2.2}\]
where \(\mu_x=\frac{1}{M}\sum_{m=1}^Mx^{(m)}\) and \(\mu_y=\frac{1}{M}\sum_{m=1}^My^{(m)}\) are the sample means, \(\tilde{s}_{xy}\) is the covariance, and \(\tilde{s}_{x}^2\) is the variance of \(x\).
Using these equations in Equation 2.2 we can simple compute the optimal values for parameters \(\theta_0\) and \(\theta_1\) for the \(M\) given training samples \({(𝑥^{(m)},𝑦^{(m)})}\).
2.3.2.2 The Normal Equation
Alternatively to the approach resulting in Equation 2.2, we can use the computation of the residuals to derive a closed form for computing the optimal parameters. Recall that we defined the residual for a sample \({(𝑥^{(m)},𝑦^{(m)})}\) as \(\varepsilon^{(m)} = y^{(m)} - \hat{y}^{(m)}\), where \(\hat{y}^{(m)} = \theta_0+\theta_1 x^{(m)}\). We can express this in matrix form as
with a correponding matrix X, where the first column contains values \(1\) and the second column contains the input values from the training set, and \(y\) contains the corresponding expected output values.
The sum of squared residuals, i.e. the loss, can be expressed as the scalar product of the residual vector with itself (for simplicity, we skip the normalization factor \(\frac{1}{2 M}\) in the derivation below):
Using some calculus, the gradient of the squared residuals yields (for the derivation see Section 2.8): \[\frac{\partial}{\partial\boldsymbol{\theta}}J = −2\boldsymbol{X}^T \boldsymbol{y}+2\boldsymbol{X}^T \boldsymbol{X} \boldsymbol{\theta}\] Equating the gradient with zero produces the so-called normal equations: \[\boldsymbol{X}^𝑇 \boldsymbol{X} \boldsymbol{\theta} = \boldsymbol{X}^T \boldsymbol{y}\] which leads to a closed form-expression for the optimal parameters: \[\boldsymbol{\theta} = (\boldsymbol{X}^T \boldsymbol{X})^{−1} \boldsymbol{X}^T \boldsymbol{y} \tag{2.3}\]
We can now use this Normal Equation to directly compute the solution for a linear regression problem: Given M training samples \({(𝑥^{(m)},𝑦^{(m)})}\), we simply construct the vector \(\boldsymbol{y}\) and the matrix \(\boldsymbol{X}\) as above, and compute the solution \(\boldsymbol{\theta}\) according to Equation 2.3. This yields the optimal values for parameters \(\theta_0\) and \(\theta_1\).
Note that the normal equation is an alternative way to solve linear regression, in addition to the closed form that we derived in Section 2.3.2.1. However, while the solution from Section 2.3.2.1 works only for the univariate case (where we have just one input value), the normal equation works also for more than one input variables, as we will see in the next section.
2.3.3 Multivariate Linear Regression
Multivariate Linear Regression, also called Multiple Linear Regression, is the natural extension of the simple linear regression framework to more than one predictor variables (features). For example, to predict the life satisfaction in a country, in addition to the GDP (\(x_1\)), also homicide rate (\(x_2\)), household net wealth (\(x_3\)), number of years in education (\(x_4\)) etc. can be employed. In this case, our input is a vector of \(N\) features \((x_1, x_2, ... x_N)\) (note that we denote the features as subscripts \(_1\), \(_2\) etc., in contrast to the sample id’s as superscripts \(^{(1)}\), \(^{(2)}\) etc.), and we want to predict an output that is as close as possible to the expected output \(y\).
One possibility would be to run four separate simple linear regressions, each of which uses a different predictor for life satisfaction. However, in this approach it is unclear how to combine the four separate predictions into a single value. Furthermore, each of the four regressions ignores the other features, which leads to incorrect estimates when features are correlated.
Thus, we now extend our simple approach for one input variable to the general case with \(N\) input variables (features). The \(N>1\) features can be combined into a single linear combination. The model then takes the following form for the \(m\)’th sample (we denote the \(i\)’th feature of the \(m\)’th sample as \(x_{i}^{(m)}\)): \[\hat{y}^{(m)} = h_{\theta}(x^{(m)}) = \theta_0 x_{0}^{(m)} + \theta_1 x_{1}^{(m)} + \theta_2 x_{2}^{(m)} + ... + \theta_N x_{N}^{(m)} = \boldsymbol{\theta}^T\boldsymbol{X}_{m,:} \tag{2.4}\] Here, we introduce a new artificial feature variable \(x_{0}^{(m)} := 1\) for all \(m=1,...,M\) to simplify the notation (i.e., writing the sum as a vector product).
Using the residuals \(\varepsilon^{(m)} = y^{(m)} - \hat{y}^{(m)}\), we can express the equation above in matrix form for all samples together: \[\boldsymbol{y} = \boldsymbol{X} \boldsymbol{\theta} + \boldsymbol{\varepsilon} \] The rules of matrix multiplication assure that this corresponds to a system of \(M\) equations of the form of Equation 2.4. The dimensions are \(\boldsymbol{X}:𝑀×(𝑁+1)\), \(\boldsymbol{\theta}:(N+1)×1\), \(\boldsymbol{y}:𝑀×1\)
For example, consider a subset of the life satisfaction data with \(M=3\), \(N=4\):
GDP per capita (USD)
Homicide rate
Household net wealth
Years in education
Happiness
\(x_0\)
\(x_1\)
\(x_2\)
\(x_3\)
\(x_4\)
y
1
29932.5
4.8
70160
18
5.9
1
31007.8
1
104458
16.4
5.6
1
32181.2
1
232666
16.9
5.4
This can be expressed using the corresponding matrices:
Note that the normal equations from Section 2.3.2.2 can also be applied to multivariate linear regression. Hence, we can plug \(X\) and \(y\) from above into Equation 2.3 to solve for the optimal model parameters \(\hat{\boldsymbol{\theta}}\).
2.4 Residual Plots
A Residual Plot is a scatter plot which has for each sample \(m\) the residual value \(\varepsilon^{(m)}\) on the vertical axis. There are different options for the values on the horizontal axis, e.g. an input variable \(x_{n}^{(m)}\) or the predicted value \(y^{(m)}\).
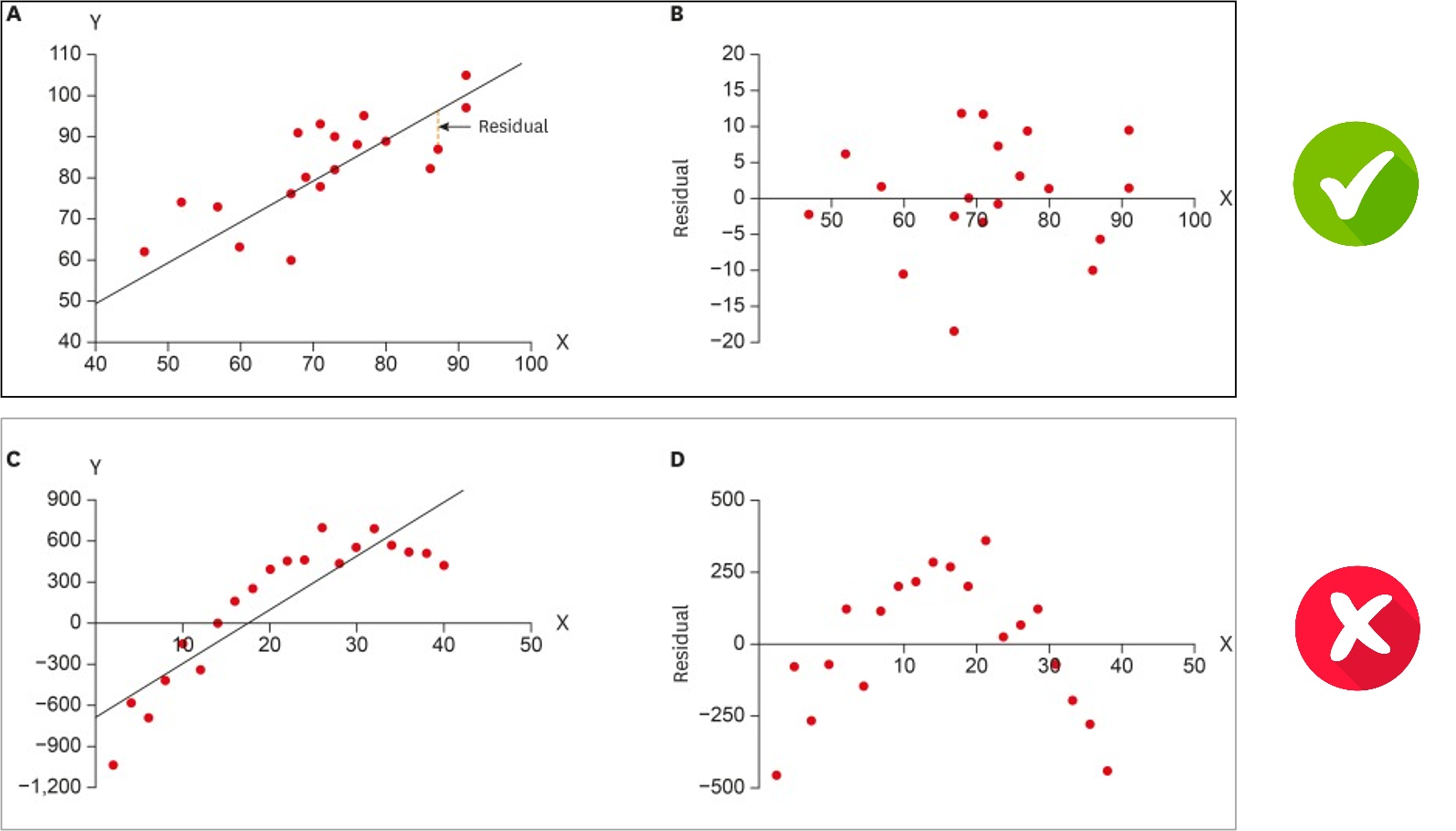
Figure 2.3: Residuals Plot: Figure A shows the original data with input X and output Y; Figure B shows the residual plot with values X on the horizontal axis. )
2.5 Basic Assumptions in Linear Regression
Applying linear regression models is only possible if several basic assumptions are valid for the data. The fundamental assumptions are: Linearity, Independence, Normality, and Homoscedasticity. If these assumptions do not hold for the data, then linear regression cannot yield reasonable results.
In the following, we explain what these assumptions are, and how they can be verified visually by means of the residual plots.
Linearity: The relationship between \(X\) and \(y\) is linear.
The fundamental assumption to apply linear regression is that there exists a linear relationship between the parameters \(x\) and the output \(y\). Figure 2.4 shows such an example. In this case, the dots are randomly scattered along the regression line. Also, most observations should lie near the regression line, while observations far away from the line are less frequent.
Figure 2.4: Top figure shows a linear relation, while bottom figure does not (left: data samples, right: residual plot)
Independence: The residuals are independent of each other.
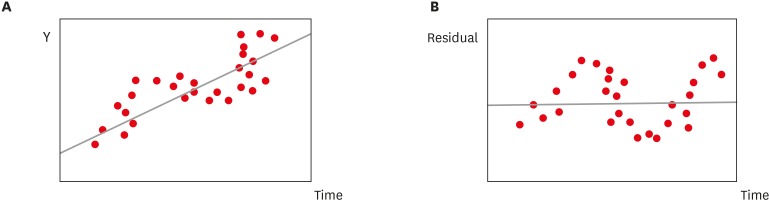
Independence assumes that the residual (the difference between the prediction and the actual outcome for one observation) does not affect or correlate with the residuals of other observations. This might be violated, for instance, if we collect data from an individual at different points in time. Figure 2.5 shows such an example, where we see a repeating pattern (autocorrelation) of the residuals over time.
Figure 2.5: Scatter plot over time, with autocorrelation pattern of the data (left: data samples, right: residual plot)
Normality: The expected output values are normally distributed.
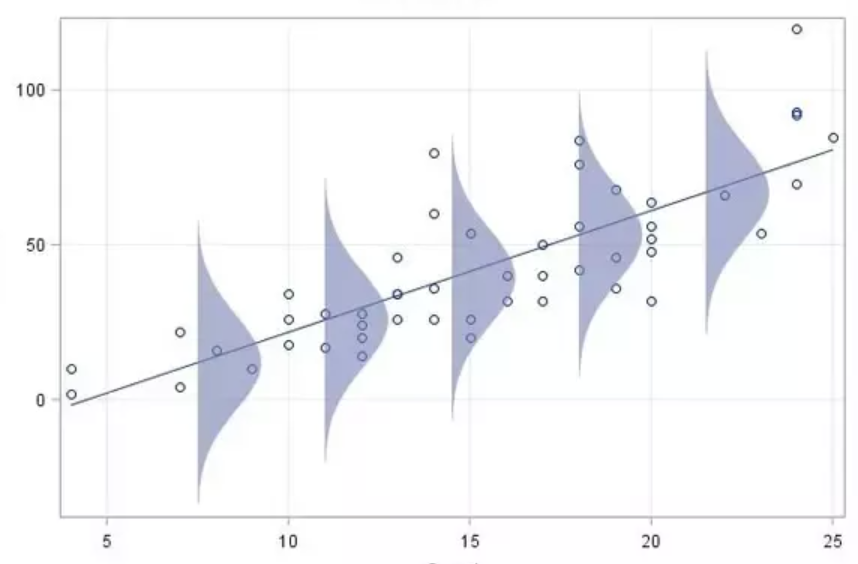
As mentioned in item “Linearity”, we assume that the there is a linear relation between input and output values. Usually, there will be some noise within samples for the same input: For instance, assume that we measure the temperature (\(x\)) and the amount of ice-cream sold on each day (\(y\)). Then even for the same temperature on different days, you would expect different amounts of ice-cream sold. However, we assume that the output values follow a normal distribution: Let \(\mu_x\) be the mean of all outputs for a give input \(x\) (e.g. for a specific temperature, the mean of all amounts of ice-cream sold on days with that temperature). Then we assume that for each input \(x\), output values close to mean \(\mu_x\) are more likely than output values further away from the mean, and that these values follow a normal distribution.
Figure 2.6: Normal distribution of outputs for each input value
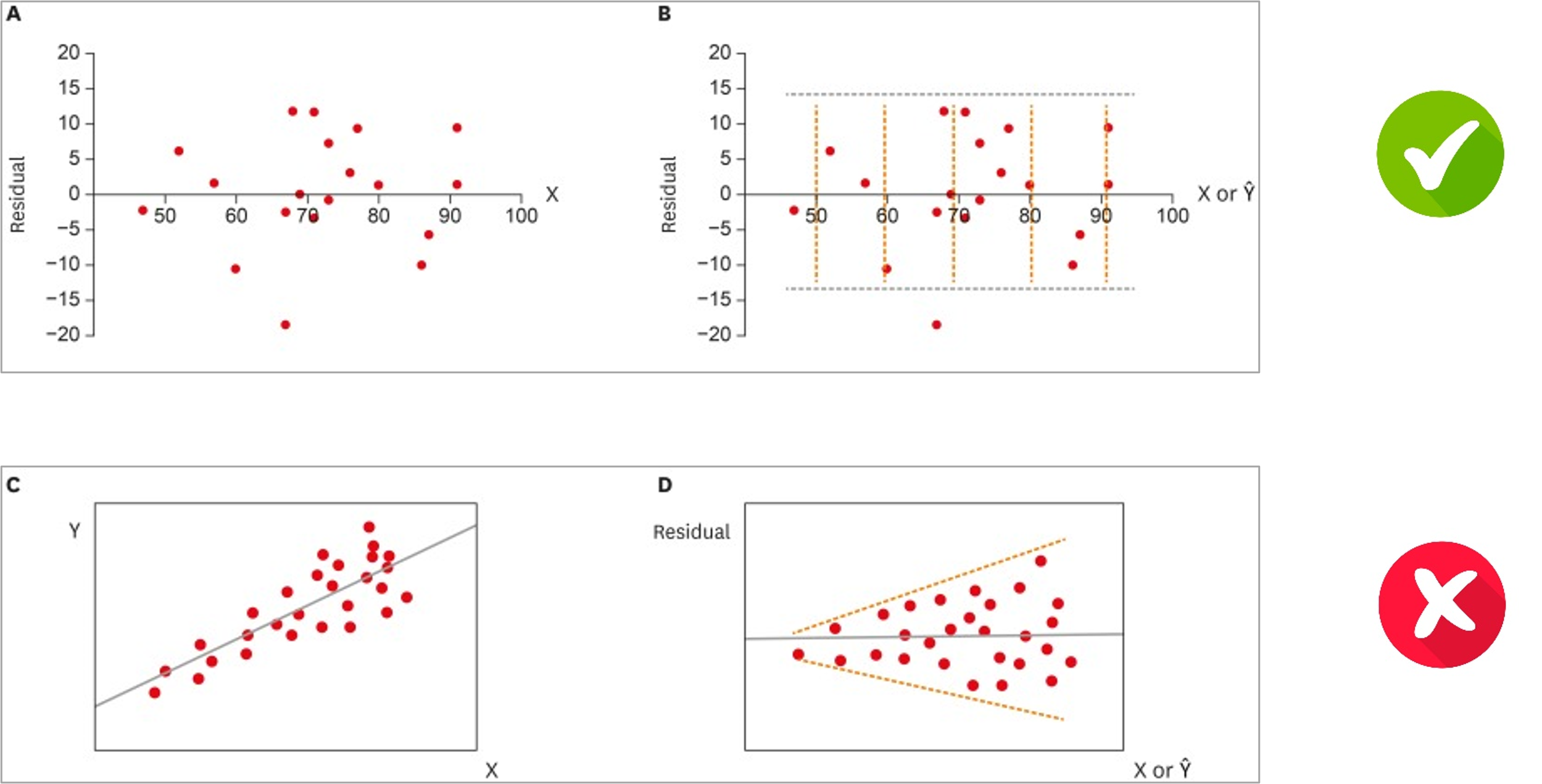
Homoscedasticity (equality of variance): The variance of the residual is the same for any value of \(X\).
In addition to normality, we also assume that the degree of variability of residuals (i.e. distance between straight line and true output values) is equal across different input values. Bottom example of Figure 2.7 shows a setting where homoscedasticity is violated, since variance increases for larger input values.
Figure 2.7: Top figure shows a setting with homoscedasdicity, while bottom figure does not (left: data samples, right: residual plot)
2.6 Evaluating Regression Models
Once a regression model is trained, we want to evaluate its quality. For this, we assess its generalisability on an independent test set (see Section 1.6.2). This test set consists of \(I\) pairs of inputs \(x^{(i)}\) and expected output values \(y^{(i)}\). The corresponding predictions of the model based on the inputs are denoted with \(\hat{𝑦}^{(i)}\). There are several metrics that can be used to quantify how well the expected and predicted output values correspond:
Mean Absolute Error: \(MAE=\frac{\sum_{𝑖=1}^𝐼|𝑦^{(i)}−\hat{𝑦}^{(i)}|}{𝐼}\)
Mean Squared Error: \(MSE=\frac{\sum_{𝑖=1}^𝐼(𝑦^{(i)}−\hat{𝑦}^{(i)})^2}{𝐼}\)
Root Mean Squared Deviation: \(𝑅𝑀𝑆𝐷=\sqrt{MSE}=\sqrt{\frac{\sum_{𝑖=1}^𝐼(𝑦^{(i)}−\hat{𝑦}^{(i)})^2}{𝐼}}\)
with \(𝐼\) number of samples in the independent test set.
Note that these errors are similar to the loss and cost function that we used when training the regression model. However, during training we used the loss on the training data to find the proper values for parameters \(\theta_i\), whereas here we assume fixed parameters \(\theta_i\) and we only evaluate how well the model performs on the test data.
2.6.1 Coefficient of Determination
One way to measure the quality of a regression model is the Coefficient of Determination \(R^2\). It measures the fraction of the variance of the data which can be explained by the model: \[𝑅^2=1−\frac{𝑆𝑆_{\text{res}}}{𝑆𝑆_{\text{tot}}}\]
where \(𝑆𝑆_{\text{res}}=\sum_i (y^{(i)} -\hat{y}^{(i)})^2=\sum_i {\varepsilon^{(i)}}^2\) is the sum of squares of residuals (also called residual sum of squares), which quantifies the variance that can not be explained by the model, and \(𝑆𝑆_{\text{tot}}=\sum_i (y^{(i)} - \mu_y)^2\) is the total sum of squared distance between each expected output \(y^{(i)}\) and the mean value over all \(y\). Note that \(𝑆𝑆_{\text{tot}}\) is proportional to the variance of the data.
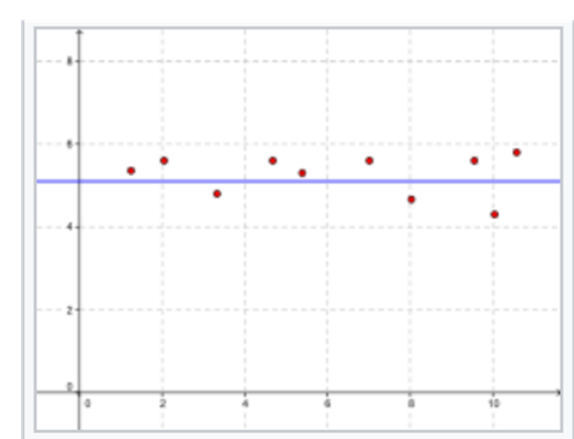
A trivial baseline model, which always predicts \(\mu_y\), will have \(𝑅^2=0\):
Figure 2.8: Baseline model which always predicts the mean (blue line) of the training data (red dots)
Models that have worse predictions than this baseline (e.g., \(\hat{y}\) is set to a constant value that is not equal \(\mu_y\)) will have a negative \(R^2\).
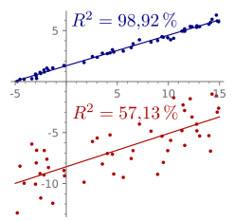
In the best case, the modeled values exactly match the observed values, which results in \(𝑆𝑆_{\text{res}}=0\) and \(𝑅^2=1\). The smaller the agreement, the smaller \(R^2\) becomes. The following figure shows two separate datasets (red and blue), and a regression line for each dataset.
Figure 2.9: High \(R^2\) value for small \(𝑆𝑆_{\text{res}}\) (blue) and smaller \(R^2\) in a situation with larger \(𝑆𝑆_{\text{res}}\) (red)
2.7 Derivation of \(\theta_0\) and \(\theta_1\) for Univariate Linear Regression
In Section 2.3.2.1, we skipped some calculus during the derivation of the explicit formula for \(\theta_0\) and \(\theta_1\). In the following, we show how this derivation of \[J=\frac{1}{2 M} \sum_{𝑚=1}^𝑀(𝑦^{(m)}−\theta_0-\theta_1 x^{(m)})^2\] is done:
We start with the partial derivative with respect to \(\theta_0\): \[\frac{\partial}{\partial𝜃_0} 𝐽 = 2\cdot(-1)\frac{1}{2M}\sum_{𝑚=1}^𝑀(𝑦^{(m)}−\theta_0-\theta_1 x^{(m)})\]
and set it to zero, since we are looking for an extremum:
Setting to zero \[ 0 = \sum_{𝑚=1}^𝑀 \theta_1 (x^{(m)}-\mu_x)^2 - \sum_{𝑚=1}^𝑀 (y^{(m)}-\mu_y)(x^{(m)}-\mu_x)\] and rearranging the resulting expression produces \[\theta_1 = \frac{\sum_{𝑚=1}^𝑀 (y^{(m)}-\mu_y)(x^{(m)}-\mu_x)}{ \sum_{𝑚=1}^𝑀 (x^{(m)}-\mu_x)^2} = \frac{\tilde{s}_{xy}}{\tilde{s}_x^2},\] where \(\tilde{s}_{xy}\) is the covariance of the input and the target values. \(\tilde{s}_{x}^2\) is the variance of the dependent variable.
2.8 Derivation of the Gradient of the Squared Residuals in Matrix Form
We now show how to compute the gradient of \(J = \boldsymbol{y}^𝑇 \boldsymbol{y}−2\boldsymbol{\theta}^𝑇 \boldsymbol{X}^𝑇 \boldsymbol{y}+\boldsymbol{\theta}^𝑇 \boldsymbol{X}^𝑇 \boldsymbol{X}\boldsymbol{\theta}\), which was skipped during the computation of the normal equation in Section 2.3.2.2.
We start with calculating the partial derivatives separately for the additive terms: \[\frac{\partial}{\partial\boldsymbol{\theta}} \boldsymbol{y}^𝑇 \boldsymbol{y} =0\]\[\frac{\partial}{\partial\boldsymbol{\theta}} \left( -2\boldsymbol{\theta}^𝑇 \boldsymbol{X}^𝑇 \boldsymbol{y}\right) =-2 \boldsymbol{X}^T \boldsymbol{y} \]
The third terms makes use of matrix calculus (see here for an overview of the most important rules): \[\frac{\partial}{\partial \boldsymbol{b}} \boldsymbol{b}^T\boldsymbol{A}\boldsymbol{b} = 2 \boldsymbol{A} \boldsymbol{b}\] for a symmetric matrix \(\boldsymbol{A}: D\times D\) and vector \(\boldsymbol{b}:D\times 1\), under the condition that \(\boldsymbol{A}\) is not a function of \(\boldsymbol{b}\).